1. 湍流模型的由来
1.1 从 NS 方程到雷诺平均 NS 方程
湍流的本质是随机、杂乱、多尺度的。在湍流中,任意物理量的瞬时值看起来像一条剧烈抖动的曲线。
因此直接求解原始 NS 方程即直接数值模拟(DNS)要求网格细到能抓住最小的湍流涡。因此对于网格尺寸和时间步长的要求都非常高。
原始 NS 动量方程(指标记号形式):
在一个 0.1 m × 0.1 m 的高雷诺数区域里,需要的网格量可以达到 10 亿到 1000 亿,时间步长要小于 100 微秒。这远远超出了普通工程计算的能力。
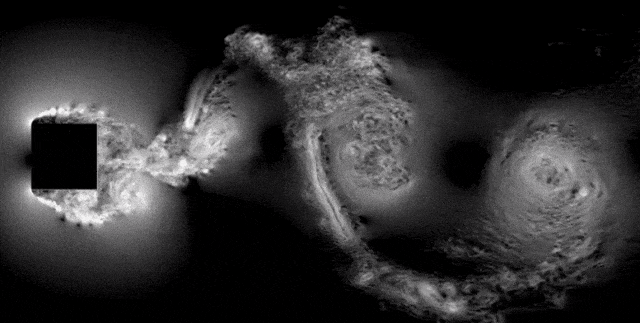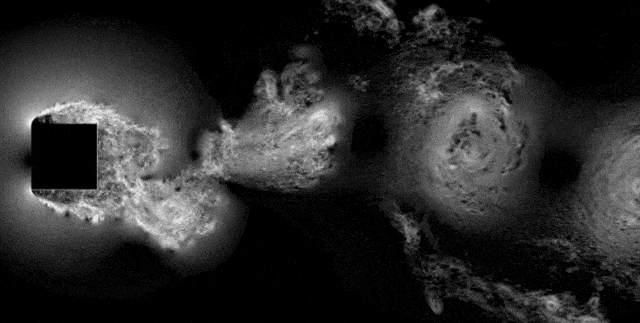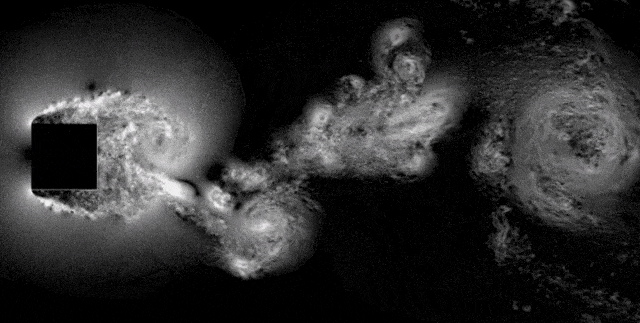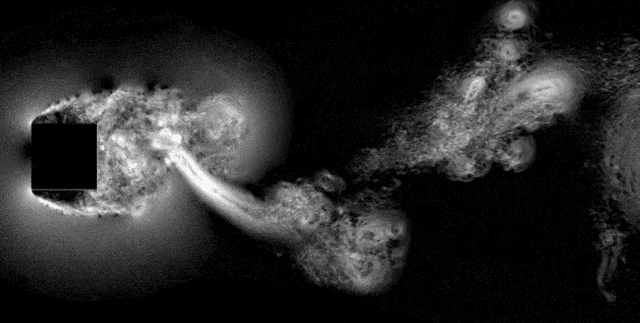
为了解决这个计算上的问题,雷诺发现,湍流中瞬时物理量的曲线其实可以分解成两部分:平均值和脉动值:
因为上下波动相互抵消,我们对脉动值求平均,结果永远是零。这一简单的性质,正是雷诺平均方法的数学基础。
原始的 NS 方程描述的是瞬时流动。把速度、压力都用"平均值 + 脉动值"代入,然后对整个方程做平均,就得到了雷诺平均 NS 方程,也就是 RANS:
与原始的 NS 方程对比,可以看到 RANS 比原始 NS 方程还多了一项——雷诺应力项:
也就是说,RANS 方程实际上是更加复杂的,那我们绕那么大的弯子转换方程的目的是什么?
我们转换方程并不是为了让方程形式上更简单,更好看,而是为了让方程更加容易求解。尽管 NS 方程形式上更加简单,但是其物理量全是瞬态量,每时每刻都在变化,这对求解精度的要求很高。
而 RANS 方程中的未知量是平均值,平均值在时间和空间上变化平缓,不需要捕捉微小的脉动。其对计算精度要求要低很多,我们可以使用较粗的网格和较大的时间步长去计算 RANS 方程。
同时,绝大多数工程问题关心的正是平均流场(比如管道平均速度、机翼平均升力)。所以 RANS 在满足工程精度的前提下,大幅降低了计算成本。
1.2 RANS 方程封闭性问题
我们决定用 RANS。但是把 RANS 方程写出来之后才发现:方程个数比未知量个数少。
原始 NS 方程:4 个方程(质量 + 三个方向动量),4 个未知量($u$、v、w、$p$),方程是封闭的,理论上可解。
连续性方程:
动量方程(以 x 方向为例):
( y、z 方向动量方程形式类似。)
RANS 方程:多出了雷诺应力项 \dfrac{\partial}{\partial x_j} (-\rho \overline{u'_i u'_j}),这一项引入了 6 个新的未知量(因为 i、j 各取三个方向,对称所以是 6 个)。
方程数量没变,未知量却变多了,不封闭,没法直接求解。所以,我们必须要做一件事:把雷诺应力用已知的平均量表示出来。
用什么方法表示?这就引出了"湍流模型"——湍流模型的核心任务就是封闭 RANS 方程。
1.3 涡粘性假设
1877 年,Boussinesq 提出了一个天才的想法:
在层流里,粘性应力 \tau_{ij} 和速度梯度(应变率)成正比,比例系数就是分子粘度 \mu:
Boussinesq 假设:湍流里的雷诺应力,也可以和平均速度梯度成正比,只不过比例系数变成了"湍流粘度" \mu_t。
公式长这样:
其中 k 就是湍动能,\delta_{ij} 是单位张量。
这个假设最大的贡献是:把 6 个雷诺应力未知量,转化成了只需要确定两个标量 \mu_t (湍流粘度)和 k (湍动能)。
现在任务一下子就清晰了:只要我们能求出 \mu_t 和 k,雷诺应力就知道了,RANS 方程就封闭了。
如何求 \mu_t 和 k?
不同的人提出了不同的方法来确定 \mu_t 和 k 。根据需要额外求解几个微分方程,就叫做几方程模型。
前面我们已经讲解了一方程模型 Spalart-Allmaras 模型,今天我们详细介绍一下二方程模型中的 k-ε 模型。
2. 几种 k-ε 模型
Fluent 软件中有三种 k-ε 模型,分别是标准 k-ε 模型、RNG k-ε 模型和 Realizable k-ε 模型。
2.1 标准的 k-ε 模型
在上文我们讲到,一方程模型需要人为给定湍流的长度尺度 l。长度尺度反映了涡的大小,直接影响湍流的混合能力。在一方程模型中,l 往往需要通过代数经验公式给出:
- 非常靠近壁面区:l \sim y^2
- 适度靠近壁面区:l \approx ky ( k = 0.4 \sim 0.41 )
- 远离壁面区:l \approx (0.075 \sim 0.09)\delta,\delta 为边界层厚度
- 如果湍流为自由剪切流,则与远离壁面区相似,l \sim b(x),b(x) 为射流宽度。
一旦流动几何复杂(如带分离、回流、多部件),这个长度尺度就很难准确给定。
而二方程中的 k-ε 模型不再需要经验指定长度尺度,适用范围广,成为工程主流。
k-ε 模型仍然沿用 Boussinesq 的涡粘性假设,比例系数是湍流粘度 \mu_t,但其用湍动能 k 和耗散率 \varepsilon 来表示 \mu_t:
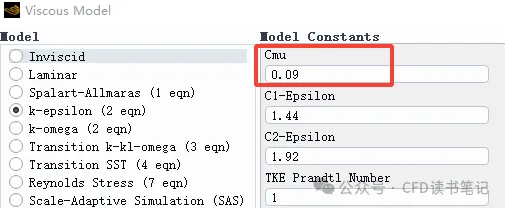
上述公式是通过量纲分析得到的,其中 C_\mu 是一个经验常数约 0.09,即 Fluent 中 k-epsilon 湍流模型中的 Cmu 参数:
这个公式非常符合物理直觉,即湍流越强 k 越大,\mu_t 越大;湍能耗散越快 \varepsilon 越大,\mu_t 越小。
现在 \mu_t 可以表示出来了,但是 k 和 \varepsilon 又怎么计算呢?k-ε 模型通过输运方程来求解 k 和 \varepsilon:
k 方程(描述湍动能的生成、扩散和耗散):
\varepsilon 方程(描述耗散率的生成、扩散和破坏):
生成项 G_k 来自平均速度梯度做功,耗散项就是 \rho\varepsilon。\varepsilon 方程并非直接推导,而是仿照 k 方程的形式构造出来的,包含生成、扩散和破坏项。它决定了湍流耗散的速率,从而间接控制湍流长度尺度的演化。
结合 \mu_t、k 和 \varepsilon 方程,可以看到公式里面出现了几个常数参数,分别是 C_\mu、C_{1\varepsilon}、C_{2\varepsilon}、\sigma_k、\sigma_\varepsilon。1974 年 Launder & Spalding 给出了这些参数非常经典的数值:
| 参数 | 数值 |
|---|---|
| C_\mu | 0.09 |
| C_{1\varepsilon} | 1.44 |
| C_{2\varepsilon} | 1.92 |
| \sigma_k | 1.0 |
| \sigma_\varepsilon | 1.3 |
之所以说这些参数经典,是因为后续的大量实验都验证了这些参数的正确性。因此除非有非常充足的理由,否则都不需要更改这些参数。
Fluent 软件中这些参数的默认值也是如此:
标准 k-ε 模型计算稳定,收敛性不错。而且有大量实验验证,对平板边界层、管流、射流精度可接受。几乎所有 CFD 软件的首选 RANS 模型。
但其也存在一些缺点,主要有:
- 无法处理强旋流:各向同性涡粘假设在强旋转流动中失效,预测的旋转效应偏弱。
- 圆管射流扩张过快:预测的射流宽度比实验宽约 40%,原因是模型过高估计了湍流粘度在射流中心的扩散。
- 近壁面依赖壁面函数:需要配合对数律壁面函数,在强压力梯度或分离区精度下降。
正是这些缺陷,催生了标准 k-ε 的两个著名改进版本:RNG k-ε 和 Realizable k-ε。
2.2 RNG k-ε 模型
RNG = Renormalization Group(重整化群),一种统计学理论方法。1986 年 Yakhot & Orzag 用数学推导修正了 \varepsilon 方程,得到 RNG k-ε。
\varepsilon 方程中增加一个附加源项 R_\varepsilon:
其中新增项 R_\varepsilon:
其中:
常数 \eta_0 = 4.38,\beta = 0.012。
如果我们把方程的 R_\varepsilon 和 C_{2\varepsilon} 这两项合并,\varepsilon 方程可以写成:
这个形式和标准 k-ε 模型的 \varepsilon 方程形式相同,但关键区别在于 C_{2\varepsilon}^* 不再是常数。
这样做的好处是在高应变率即 \eta 大的区域,比如强旋流、壁面弯曲处,C_{2\varepsilon}^* 会自动增大,从而增强 \varepsilon 方程中的破坏项,湍流耗散率 \varepsilon 会被"推高",导致湍流粘度 \mu_t 降低,从而削弱过于强烈的湍流混合,改善对旋流和分离的预测。
而在低应变率区域,\eta 趋向于 0,R_\varepsilon 也会趋向于 0,此时 RNG 模型会变成标准的 k-ε 模型。
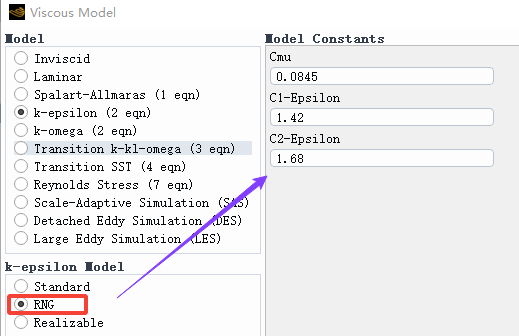
所以我们可以看到,RNG 模型对标准模型进行了拓展,使得标准模型对于高应变率的预测更加精确。同时 RNG 模型的常数取值也和标准模型不同,从理论上计算出 C_\mu \approx 0.0845,其他参数取值为 C_{1\varepsilon} = 1.42、C_{2\varepsilon} = 1.68。
而在 Fluent 软件中,RNG 模型通常采用有效粘度比来插值得到 \sigma_k、\sigma_\varepsilon,不再使用固定值,因此界面中没有这两个参数的设置:
除了上述的参数设置,RNG 模型还有两个附带的选项,这部分内容我们在第三节的界面介绍中详细说明。
总结一下,RNG k-ε 模型对于强应变率敏感,对分离流和旋转流更准确,适用于射流、旋风分离器等流动。但其本质上仍然是针对高雷诺数的湍流模型,且会多消耗 10%–15% 左右的 CPU 时间。
2.3 Realizable k-ε 模型
前面我们介绍了标准的 k-ε 模型和 RNG k-ε 模型。标准的 k-ε 模型设置了 5 个常数参数,RNG k-ε 模型将常数参数中的 C_{2\varepsilon} 表达成了应变率的方程,使得模型更加适用于强应变率流动。
这两种模型都假定 C_\mu 是常数。这个假设在平板边界层、圆管流中效果不错,但一旦遇到强应变率或大曲率的流动,就会出现问题。
最经典的例子是圆管射流:实验发现,射流核心区的湍流粘度应该远低于标准模型的预测,导致射流扩张速度比实验值快约 40%。为什么标准模型会高估 \mu_t?
因为 k^2/\varepsilon 在射流中心被算得偏大,但 C_\mu 又被锁死在 0.09,导致湍流粘度过大。从物理角度上,雷诺应力也必须满足一些物理约束。
因此为了达到这一目的,1995 年 Shih 等人提出了 Realizable k-ε 模型,核心目标就是:让 C_\mu 不再是常数,而是随平均流场动态调整,并精准预测射流扩张。
Realizable 模型中的 C_\mu 表达式为:
其中:
S_{ij} 是平均应变率张量,\Omega_{ij} 是平均旋转率张量(考虑角速度)。
当平均应变率 S 很大时,U^* 变大,分母中 A_s U^* k/\varepsilon 项占主导,C_\mu 会自动减小,湍流粘度就会降低,这就达到了对湍流预测的限制作用。
同时 Realizable 模型还对 \varepsilon 方程进行了改进。标准模型的 \varepsilon 方程来源于经验推导,并非严格理论推导。
Realizable 模型从输运方程出发推导得到 \varepsilon 方程:
- 生成项:\rho C_1 S \varepsilon,和标准的 \varepsilon 方程相比,直接用 S 乘以 \varepsilon,避免了 k 在分母上引起的奇异行为。
- 破坏项:分母中加了 \sqrt{\nu\varepsilon},保证在近壁区不会发散。
我们总结一下,Realizable k-ε 模型重新推导 C_\mu 和 \varepsilon 方程,使雷诺应力满足物理可实现条件,因此在旋转均匀剪切流、包含有射流和混合流的自由流动、管道内流动、边界层流动,以及带有分离的流动中通常最好。
Fluent 理论手册中专门指出:Realizable 模型能够更准确预测射流扩散率。
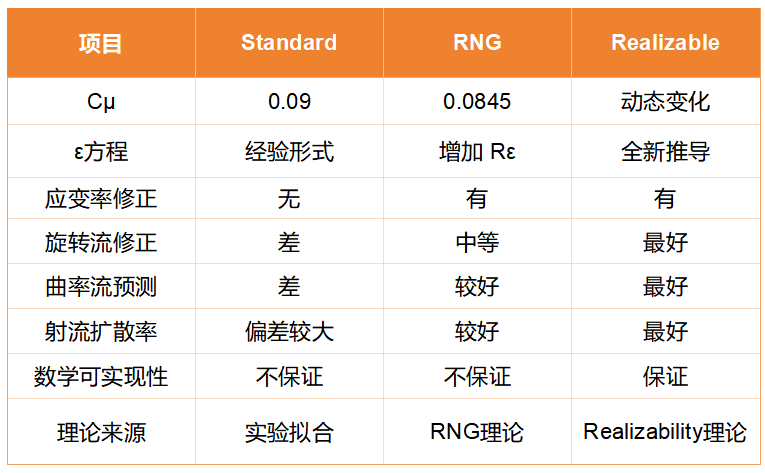
2.4 三种 k-ε 模型对比
我们借助 AI 来总结生成三种模型的对比表格:
3. Fluent k-ε 模型界面
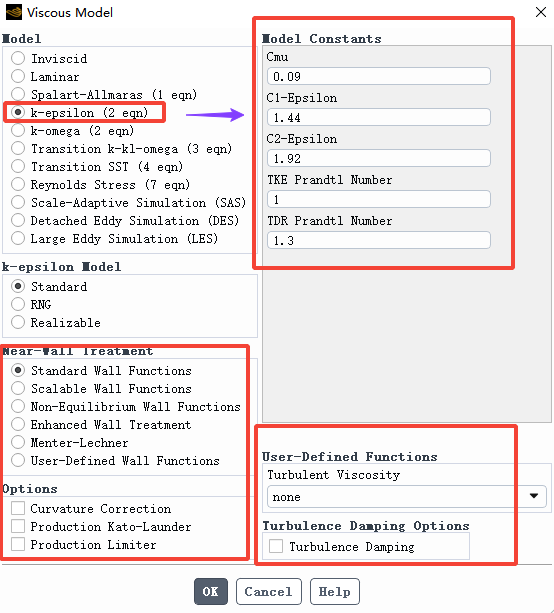
3.1 标准 k-ε 模型界面
我们这里只说每个湍流模型附加的参数设置,对于通用的参数这里暂且不提。
对于标准 k-ε 模型,需要设置的就是界面右上的几个常数参数,也就是 2.1 节给出的参数:
C_\mu=0.09、C_{1\varepsilon}=1.44、C_{2\varepsilon}=1.92、\sigma_k=1.0、\sigma_\varepsilon=1.3
这些常数经过了大量的工程检验,一般不需要修改。或者说,如果你想修改这些参数,那你就要给出能够说服别人的理由。
3.2 RNG k-ε 模型界面
RNG k-ε 模型界面也需要设置一些常数参数,这里在 2.2 节已经介绍过。下面我们重点说说 RNG Options 的设置:
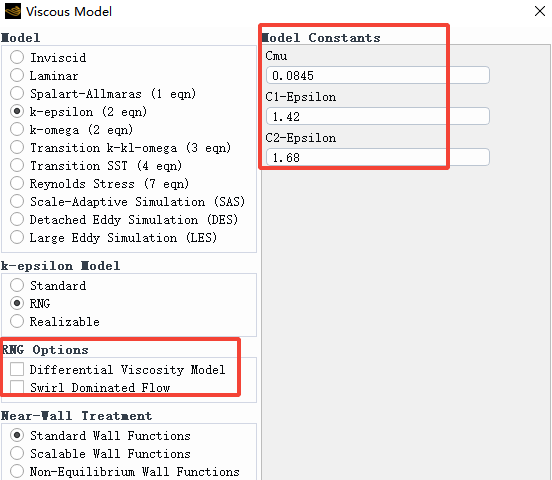
Differential Viscosity Model:勾选此选项,表示使用有效粘度 \mu_{eff} 的微分公式来考虑低雷诺数效应:
其中 \hat{\nu} = \mu_{eff}/\mu,表示有效粘度与分子粘度之比。
这个微分方程能更好地描述从粘性底层到对数律区的过渡。可以借此选择低雷诺数 RNG 模式,直接积分到壁面,而不依赖壁面函数。
Swirl Dominated Flow:RNG 模型在强旋流中可以开启旋流修正。此时湍流粘度 \mu_t 会乘以一个与旋流数相关的函数:
这时界面会多出一个参数设置:
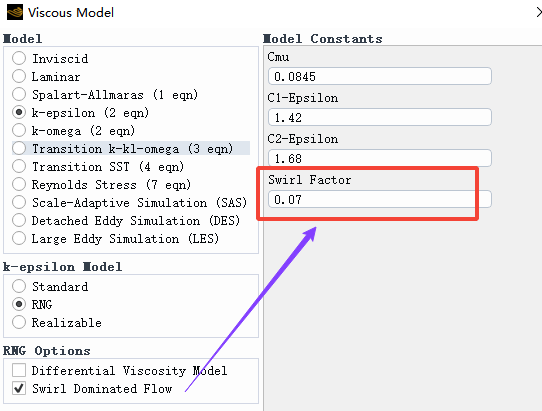
Fluent 中提供了旋流常数 \alpha_s,默认 0.07。对于强旋流,可将其提高到 0.1 左右,进一步抑制过高的湍流粘度。
3.3 Realizable k-ε 模型
Realizable k-ε 模型需要设置一些常数参数,一般保持默认即可:
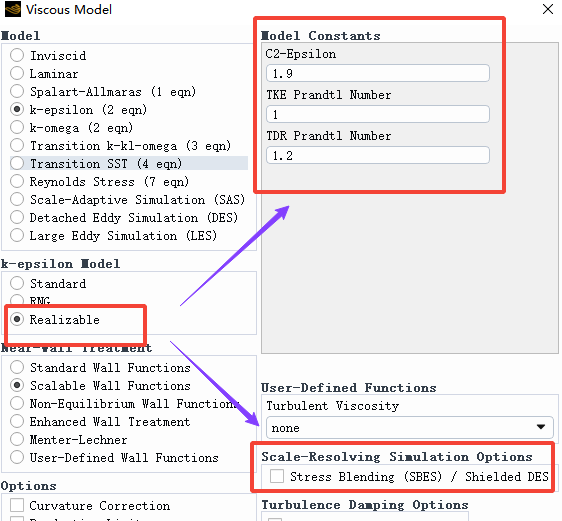
除了常数参数外,Realizable k-ε 模型还可以启用 SBES 或者是 SDES 模型,也就是勾选 Stress Blending(SBES)/ Shielded DES。
勾选这个选项后,设置比较复杂,这里我们只说明这个选项的作用,不详细介绍:
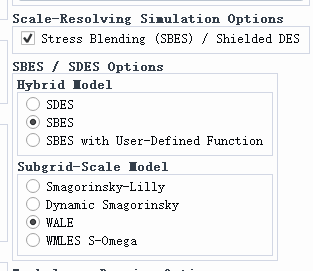
勾选这个选项之后,相当于 RANS 控制方程植入 LES 功能,是一种混合 RANS-LES 方法。用 RANS 来处理附着边界层,用 LES 捕捉远离壁面的大尺度分离涡。